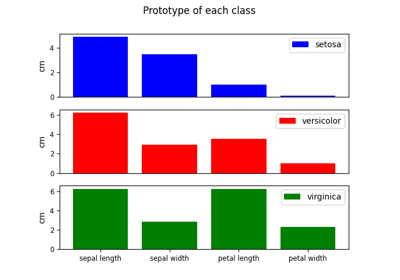
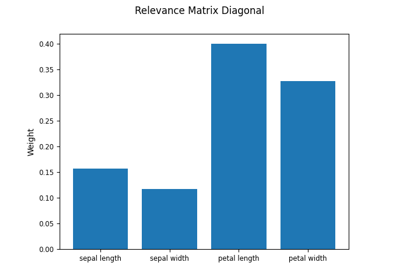
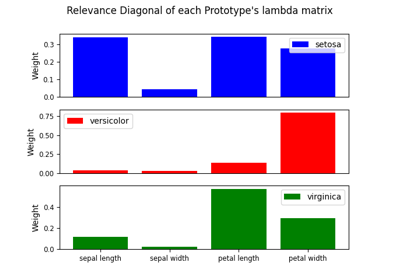
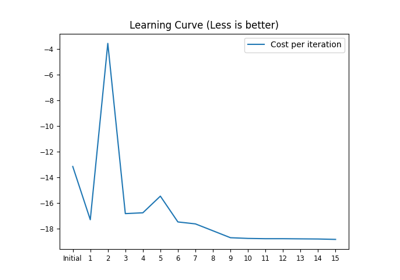
sklvq.models.LVQBaseClass
- class sklvq.models.LVQBaseClass(distance_type: str | type = 'squared-euclidean', distance_params: dict | None = None, valid_distances: list[str] | None = None, solver_type: str | type = 'steepest-gradient-descent', solver_params: dict | None = None, valid_solvers: list[str] | None = None, prototype_init: str = 'class-conditional-mean', prototype_n_per_class: int = 1, random_state: int | RandomState = None, force_all_finite: str | bool = True)[source]
Learning Vector Quantization base class
Abstract class for implementing LVQ models. It provides abstract methods with expected call signatures.
Provides a common interface to the solver and other function that require access to the models. Additionally, it implements a number of functions shared by the currently implemented LVQ variations.
- __init__(distance_type: str | type = 'squared-euclidean', distance_params: dict | None = None, valid_distances: list[str] | None = None, solver_type: str | type = 'steepest-gradient-descent', solver_params: dict | None = None, valid_solvers: list[str] | None = None, prototype_init: str = 'class-conditional-mean', prototype_n_per_class: int = 1, random_state: int | RandomState = None, force_all_finite: str | bool = True)[source]
- abstract add_partial_gradient(gradient, partial_gradient, i_prototype) None[source]
To increase performance, the distance gradient methods (should) return only the relevant values. I.e., the gradient of the prototype i_prototype and potentially other parameters linked to this prototype. This partial gradient needs to added (overwrite) to the correct parts of the actual gradient and this is what this function should do.
- Parameters:
- gradientndarray
Same shape as the
get_variables()would return.- partial_gradientndarray
1d array containing the partial gradient.
- i_prototypeint
The index of the prototype to which the partial gradient was computed.
- decision_function(X: ndarray)[source]
Evaluates the decision function for the samples in X. Shape for binary class is (n_observations,) with the decision values for the “greater” class. In the multiclass case it returns decision values for each class and therefore has the shape (n_observations, n_classes).
- Parameters:
- Xndarray
The data.
- Returns:
- decision_valuesndarray
Binary case shape is (n_observations,) and the multiclass case (n_observations, n_classes)
- fit(X: ndarray, y: ndarray)[source]
- Fit function that provides the general implementation of the LVQ algorithms. It checks the data, calls
before_fit method, calls the solve method of the solver, and the after_fit method.
- Parameters:
- Xndarray of shape (number of observations, number of dimensions)
- yndarray of size (number of observations)
- Returns:
- self
The trained model
- get_metadata_routing()
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- abstract get_model_params() tuple | ndarray[source]
Should return a view or tuple of views (in correct shape) of the model’s parameters. Implementation depends on specific model as model parameters may differ per model.
- Returns:
- ndarray or tuple
View or tuple of views of the model’s parameters.
- get_params(deep=True)
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- get_prototypes() ndarray[source]
Return a view into
self._variablesof the the shape of the prototypes (n_prototypes, n_features). At the moment only consistency function, does not actually create the shape and only works afterself.prototypes_has been set.- Returns:
- prototypesndarray of shape (n_prototypes, n_features)
View into
self._variableswith shape specified above.
- get_variables() ndarray[source]
Returns the
self._variablesarray that owns the memory allocated for the model parameters.- Returns:
- _variablesndarray
returns the model’s _variables array.
- abstract mul_step_size(step_size: float | ndarray, gradient: ndarray) None[source]
Should multiply the provided gradient with the provided step size and overwrite the values in
gradient. Depending on thestep_sizebeing a float or array different step sizes are used for different model parameters (which also depends on the model if there are more then only prototypes)- Parameters:
- step_sizefloat or ndarray
The scalar or list of values containing the step sizes.
- gradientndarray
Same shape as the
get_variables()would return.
- abstract normalize_variables(var_buffer: ndarray) None[source]
Should modify the var_buffer as if it was the variables array provided by
get_variables().- Parameters:
- var_bufferndarray
Array with the same size as the model’s variables array as returned by
get_variables().
- Returns:
- ndarray or tuple
Same shape and size as input, but normalized. How to normalize depends on model implementation.
- predict(X: ndarray, threshold: float = 0.5)[source]
Predict function
The decision is made for the label of the prototype with the minimum decision value, as provided by the
decision_function(). To choose a different cutoff point (e.g., based upon ROC analysis for 2-class data),thresholdcan be set, which acts on the values frompredict_proba(). The threshold value won’t be used when the model has been fitted to data with more than 2 classes.- Parameters:
- Xndarray
The data.
- thresholdfloat
threshold for
predict_proba()values (default 0.5), should be in the interval [0,1]
- Returns:
- ndarray of shape (n_observations)
Returns the predicted labels.
- predict_proba(X: ndarray)[source]
- Parameters:
- Xndarray
The data.
- Returns:
- confidence_scoresndarray of shape (n_observations, n_classes)
- score(X, y, sample_weight=None)
Return the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test samples.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
True labels for X.
- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- scorefloat
Mean accuracy of
self.predict(X)w.r.t. y.
- abstract set_model_params(new_model_params: tuple | ndarray)[source]
Should modify the
self._variablesarray. Accepts the new_model_params in the shape of the model’s parameters, e.g., prototypes or (prototypes, relevance_matrix).Always needs to be all the model parameters, can not be used for partial updates.
- Parameters:
- new_model_paramsndarray or tuple
Array or tuple of arrays of the new model’s parameters.
- set_params(**params)
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_predict_request(*, threshold: bool | None | str = '$UNCHANGED$') LVQBaseClass
Request metadata passed to the
predictmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- thresholdstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
thresholdparameter inpredict.
- Returns:
- selfobject
The updated object.
- set_prototypes(new_prototypes: ndarray) None[source]
Accepts a new_prototypes array with the same shape as
self.prototypes_and overwrites theself._variablesarray by copying the values of the new_prototypes.- Parameters:
- new_prototypesndarray of shape (n_prototypes, n_features)
The new prototypes the model should store.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LVQBaseClass
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
- set_variables(new_variables: ndarray) None[source]
Modifies the
self._variablesby copying the values ofnew_variablesinto the memory ofself._variables.- Parameters:
- new_variablesndarray
1d numpy array that contains all the model parameters in continuous memory
- abstract to_model_params_view(var_buffer: ndarray) tuple | ndarray[source]
Should return a single view into the var_buffer or a tuple of views. This depends on the model and its parameters.
- Parameters:
- var_bufferndarray
Array with the same size as the model’s variables array as returned by
get_variables().
- Returns:
- ndarray or tuple
Should return a view or tuple of views of the model parameters in appropriate shapes.
- abstract to_prototypes_view(var_buffer: ndarray) ndarray[source]
Should return the prototypes from the provided var_buffer. I.e., it selects/views the appropriate part of memory and reshapes it.
- Parameters:
- var_bufferndarray
Array with the same size as the model’s variables array as returned by
get_variables().
- Returns:
- ndarray of shape (n_prototypes, n_features)
View into the var_buffer.