Note
Click here to download the full example code
Generalized Matrix LVQ (GMLVQ)¶
Example of how to use GMLVQ [1] on the classic iris dataset.
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
from sklvq import GMLVQ
matplotlib.rc("xtick", labelsize="small")
matplotlib.rc("ytick", labelsize="small")
# Contains also the target_names and feature_names, which we will use for the plots.
iris = load_iris()
data = iris.data
labels = iris.target
feature_names = [name[:-5] for name in iris.feature_names]
Fitting the Model¶
Scale the data and create a GLVQ object with, e.g., custom distance function, activation function and solver. See the API reference under documentation for defaults and other possible parameters.
# Sklearn's standardscaler to perform z-transform
scaler = StandardScaler()
# Compute (fit) and apply (transform) z-transform
data = scaler.fit_transform(data)
# The creation of the model object used to fit the data to.
model = GMLVQ(
distance_type="adaptive-squared-euclidean",
activation_type="swish",
activation_params={"beta": 2},
solver_type="waypoint-gradient-descent",
solver_params={"max_runs": 10, "k": 3, "step_size": np.array([0.1, 0.05])},
random_state=1428,
)
The next step is to fit the GMLVQ object to the data and use the predict method to make the predictions. Note that this example only works on the training data and therefor does not say anything about the generalizability of the fitted model.
# Train the model using the scaled data and true labels
model.fit(data, labels)
# Predict the labels using the trained model
predicted_labels = model.predict(data)
# To get a sense of the training performance we could print the classification report.
print(classification_report(labels, predicted_labels))
Out:
precision recall f1-score support
0 1.00 1.00 1.00 50
1 0.98 0.96 0.97 50
2 0.96 0.98 0.97 50
accuracy 0.98 150
macro avg 0.98 0.98 0.98 150
weighted avg 0.98 0.98 0.98 150
Extracting the Relevance Matrix¶
In addition to the prototypes (see GLVQ example), GMLVQ learns a matrix lambda_ which can tell us something about which features are most relevant for the classification.
# The relevance matrix is available after fitting the model.
relevance_matrix = model.lambda_
# Plot the diagonal of the relevance matrix
fig, ax = plt.subplots()
fig.suptitle("Relevance Matrix Diagonal")
ax.bar(feature_names, np.diagonal(relevance_matrix))
ax.set_ylabel("Weight")
ax.grid(False)
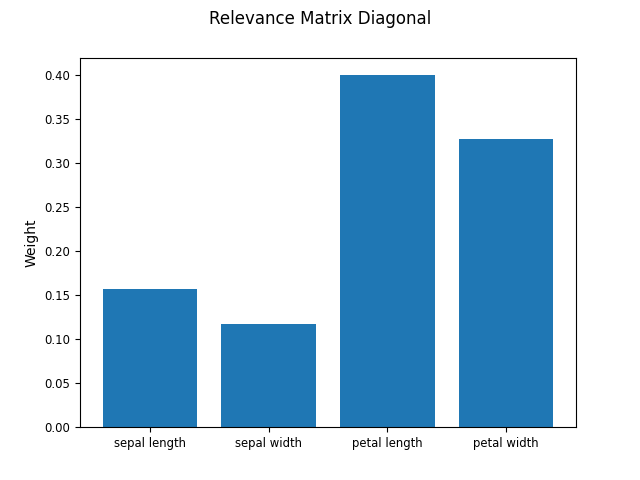
Note that the relevance diagonal adds up to one. The most relevant features for distinguishing between the classes present in the iris dataset seem to be (in decreasing order) the petal length, petal width, sepal length, and sepal width. Although not very interesting for the iris dataset one could use this information to select only the top most relevant features to be used for the classification and thus reducing the dimensionality of the problem.
Transforming the data¶
In addition to making predictions GMLVQ can be used to transform the data using the eigenvectors of the relevance matrix.
# Transform the data (scaled by square root of eigenvalues "scale = True")
transformed_data = model.transform(data, scale=True)
x_d = transformed_data[:, 0]
y_d = transformed_data[:, 1]
# Transform the model, i.e., the prototypes (scaled by square root of eigenvalues "scale = True")
transformed_model = model.transform(model.prototypes_, scale=True)
x_m = transformed_model[:, 0]
y_m = transformed_model[:, 1]
# Plot
fig, ax = plt.subplots()
fig.suptitle("Discriminative projection Iris data and GMLVQ prototypes")
colors = ["blue", "red", "green"]
for i, cls in enumerate(model.classes_):
ii = cls == labels
ax.scatter(
x_d[ii],
y_d[ii],
c=colors[i],
s=100,
alpha=0.7,
edgecolors="white",
label=iris.target_names[model.prototypes_labels_[i]],
)
ax.scatter(x_m, y_m, c=colors, s=180, alpha=0.8, edgecolors="black", linewidth=2.0)
ax.set_xlabel("First eigenvector")
ax.set_ylabel("Second eigenvector")
ax.legend()
ax.grid(True)
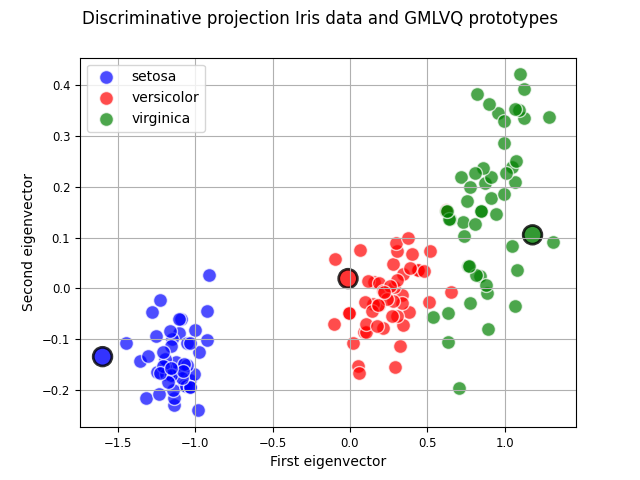
The transformed data and prototypes can be used to visualize the problem in a lower dimension, which is also the space the model would compute the distance. The axis are the directions which are the most discriminating directions (combinations of features). Hence, inspecting the eigenvalues and eigenvectors (axis) themselves can be interesting.
# Plot the eigenvalues of the eigenvectors of the relevance matrix.
fig, ax = plt.subplots()
fig.suptitle("Eigenvalues")
ax.bar(range(0, len(model.eigenvalues_)), model.eigenvalues_)
ax.set_ylabel("Weight")
ax.grid(False)
# Plot the first two eigenvectors of the relevance matrix, which is called `omega_hat`.
fig, ax = plt.subplots()
fig.suptitle("First Eigenvector")
ax.bar(feature_names, model.omega_hat_[:, 0])
ax.set_ylabel("Weight")
ax.grid(False)
fig, ax = plt.subplots()
fig.suptitle("Second Eigenvector")
ax.bar(feature_names, model.omega_hat_[:, 1])
ax.set_ylabel("Weight")
ax.grid(False)


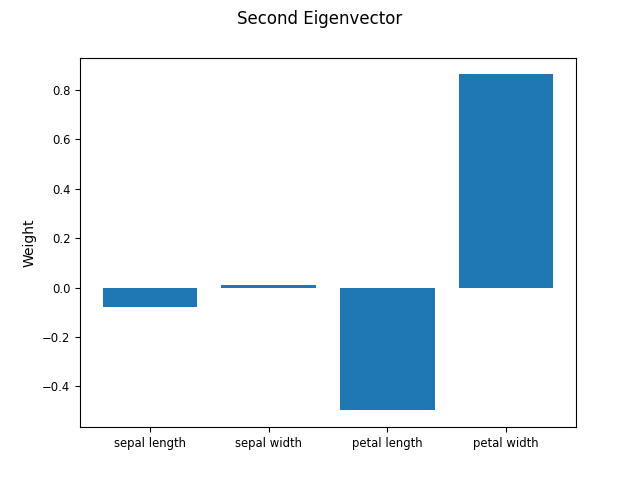
In the plots from the eigenvalues and eigenvector we see a similar effects as we could see from just the diagonal of lambda_. The two leading (most relevant or discriminating) eigenvectors mostly use the petal length and petal width in their calculation. The diagonal of the relevance matrix can therefor be considered as a summary of the relevances of the features.
References¶
[1] Schneider, P., Biehl, M., & Hammer, B. (2009). “Adaptive Relevance Matrices in Learning Vector Quantization” Neural Computation, 21(12), 3532–3561, 2009.
Total running time of the script: ( 0 minutes 0.477 seconds)