Basic Usage¶
Examples of how to fit, predict, and transform (when applicable) the data with each of the LVQ algorithms.
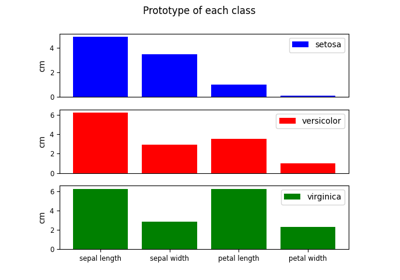
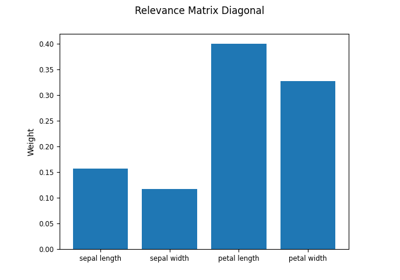


Pre-processing¶
Any pre-processing, can be achieved by using the by sklearn’s pipelines. Therefore, this section will not discuss the topic in detail but provide a basic example of how one would do this using a model from the sklvq package.

Model Selection¶
This section contains how one could use sklearn’s crossvalidation and gridsearch methods in combination with the models provided in the sklvq package.


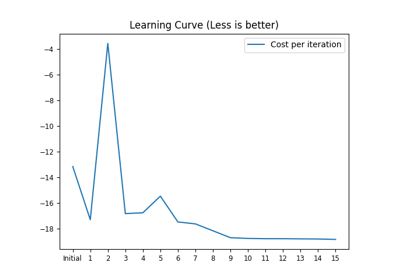

Customization¶
The algorithms accept custom activation, discriminant and distance functions, as well as solvers. Any customization with proper testing and documentation will be considered to be included in the sklvq package. Please, create a pull request on github.
Custom models and objectives are also welcome. However, as they greatly impact all currently implemented parts and even might work completely differently there is no easy way to make this similarly expandable as what currently is.



