sklvq.solvers.WaypointGradientDescent¶
-
class
sklvq.solvers.WaypointGradientDescent(objective: sklvq.objectives._base.ObjectiveBaseClass, max_runs: int = 10, step_size: Union[float, numpy.ndarray] = 0.1, loss: float = 0.6666666666666666, gain: float = 1.1, k: int = 3, callback: Optional[callable] = None)[source]¶ Waypoint gradient descent (WGD)
Implements the waypoint average optimization algorithm [1]. Implementation and description is inspired by [2].
The algorithm keeps a rolling average of the last
kmodel parameters. Afterksteps the algorithms will compare the cost of the average model parameters (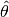 ) versus a “regular” update of the model parameters (
) versus a “regular” update of the model parameters (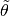 ).
).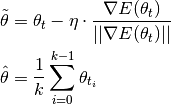
If the regular step results in a lower cost (
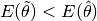 ), the
), the step_sizeis increased by multiplying with thegainfactor: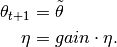
If the average step results in a lower cost ((
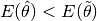 ) the
) the step_sizeis decreased by multiplying with thelossfactor: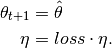
Note that the solver uses the normalized objective gradient to update the model.
- Parameters
- objective: ObjectiveBaseClass, required
- This is set by the algorithm. See
sklvq.models.GLVQ,sklvq.models.GMLVQ, and
sklvq.models.LGMLVQ.
- This is set by the algorithm. See
- max_runs: int
Maximum number of runs/epochs that will be computed. Should be >= k. Early stopping can be implemented by providing a
callbackfunction that returns True when the solver should stop.- step_size: float or ndarray
The step size to control the learning rate of the model parameters. If the same step size should be used for all parameters (e.g., prototypes and omega) then a single float is sufficient. If separate initial step_sizes should be used per model parameter then this should be specified by using a ndarray.
Whenever the averge update is accepted (has a lower cost) the step sizes are multiplied with the
lossfactor. When the “regular” update is accepted then the step size(s) are multiplied by thegainfactor.- loss: float
Should be a value less than 1. Controls the step size change factor when an average waypoint step is accepted.
- gain: float
Should be a value greater than 1. Controls the step size change factor when a regular update step is accepted.
- k: int
The number of runs used to compute the average waypoint over.
- callback: callable
Callable with signature callable(state). If the callable returns True the solver will stop even if max_runs is not reached yet. The state object contains the following:
- “variables”
Concatenated 1D ndarray of the model’s parameters
- “nit”
The current iteration counter.
- “fun”
The accepted cost.
- “nfun”
The cost of the regular update step.
- “tfun”
The cost of the “tentative” update, i.e., the average of the past k updates.
- “step_size”
The current step_size(s)
References
[1] Papari, G., and Bunte, K., and Biehl, M. (2011) “Waypoint averaging and step size control in learning by gradient descent” Mittweida Workshop on Computational Intelligence (MIWOCI) 2011.
[2] LeKander, M., Biehl, M., & De Vries, H. (2017). “Empirical evaluation of gradient methods for matrix learning vector quantization.” 12th International Workshop on Self-Organizing Maps and Learning Vector Quantization, Clustering and Data Visualization, WSOM 2017.
-
solve(data: numpy.ndarray, labels: numpy.ndarray, model: LVQBaseClass)[source]¶ Solve function that gets called by the fit method of the models.
Performs the steps of the waypoint gradient descent optimization method.
- Parameters
- datandarray of shape (n_samples, n_features)
The data.
- labelsndarray of size (n_samples)
The labels of the samples in the data.
- modelLVQBaseClass
The initial model that will also hold the final result